
AI Fluency vs AI Literacy: The DOL Just Set the Standard — Here's How to Measure It
The U.S. Department of Labor defined AI literacy for the American workforce. AISA's AI fluency assessment covers 100% of it — all 25 sub-competencies — and measures proficiency depth the framework doesn't reach.
AI fluency — the demonstrated ability to work effectively with AI tools, not just understand what they are — is becoming the defining workforce skill of 2026. But what does it actually look like in practice, and how should employers measure it?
In February 2026, the U.S. Department of Labor answered the first question. Training and Employment Notice No. 07-25 — a formal directive to every state workforce board, American Job Center, and community college in America — established the federal government's AI Literacy Framework. It defines 5 content areas, 25 sub-competencies, and 7 delivery principles that set the baseline for what the American workforce needs to know about AI.
We cross-referenced every sub-competency against AISA's assessment methodology. The result: AISA covers 100% of the DOL's framework — and measures the proficiency depth the framework doesn't reach.
What Is AI Fluency?
AI fluency goes beyond AI literacy. Where literacy asks "do you understand AI?", fluency asks "can you work effectively with it?"
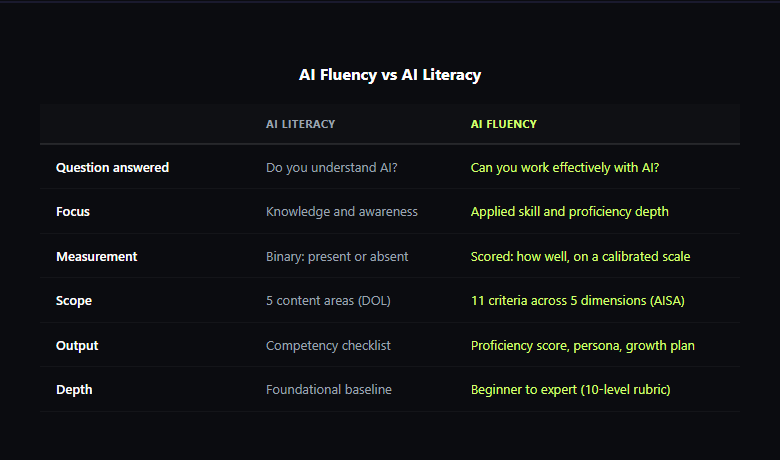
The distinction matters. Someone can explain what a large language model is (literate) without knowing how to structure a prompt that gets useful results, verify the output, or integrate AI into a daily workflow (fluent). Literacy is knowledge. Fluency is applied skill.
The DOL itself acknowledges this spectrum. The framework notes that "AI literacy serves as the baseline for engaging with AI tools in any job, while acknowledging that many roles will require more advanced capabilities beyond this foundational level." Some discussions use terms like "AI proficiency" or "AI fluency" to imply different levels of mastery — and the DOL explicitly calls for employers to "define the specific AI skills and depth of knowledge, or levels of proficiency, appropriate for each role and context."
That's where an AI fluency assessment comes in. AISA's assessment measures the full spectrum — from foundational understanding to expert-level proficiency — across 11 criteria and 5 dimensions. The DOL's framework defines the literacy baseline. Here's how the two relate.
What Is the DOL AI Literacy Framework?
TEN 07-25 is not a policy suggestion — it's a formal directive from the Employment and Training Administration, issued in response to Executive Order 14277 (Advancing Artificial Intelligence Education for American Youth) and the White House's AI Action Plan. It was sent to every state workforce agency, every American Job Center, every community and tribal college, every Job Corps centre, and every state educational agency in the country.
The DOL defines AI literacy as "a foundational set of competencies that enable individuals to use and evaluate AI technologies responsibly, with a primary focus on generative AI."
The framework is organised into five content areas, each with five sub-competencies:
- Understand AI Principles — how AI works, its capabilities and limitations, hallucinations, the role of human oversight
- Explore AI Uses — practical applications across productivity, creativity, decision-support, and task-specific workflows
- Direct AI Effectively — prompting, providing context, iterating on outputs, avoiding vague instructions
- Evaluate AI Outputs — verifying accuracy, spotting logical errors, aligning with intent, applying human judgment
- Use AI Responsibly — data protection, workplace policies, context-specific risk management, maintaining accountability
That gives us 25 specific sub-competencies — a concrete, auditable checklist for what "AI literate" means at the federal level.
How the DOL's 25 Sub-Competencies Map to AISA
Every DOL sub-competency maps to at least one AISA criterion. But where the DOL defines five broad areas, AISA's methodology decomposes them into 11 distinct, independently scored criteria — more than doubling the granularity.
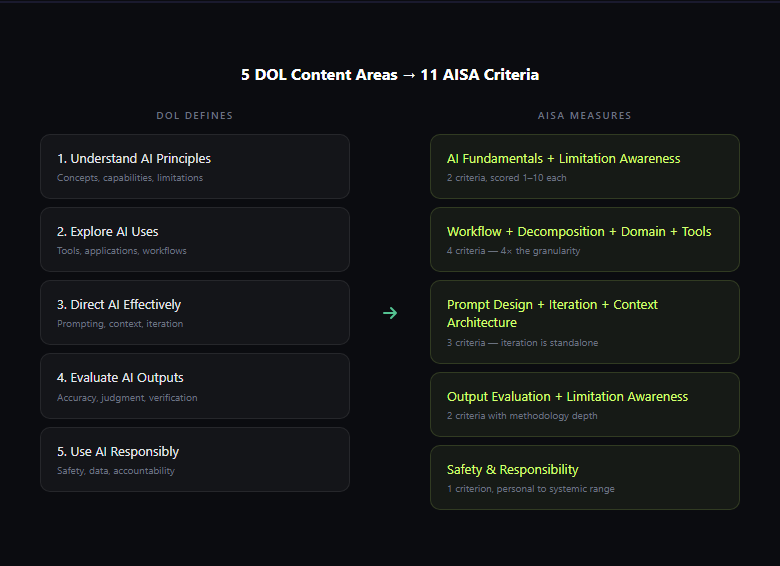
Here's what the mapping reveals:
The DOL treats prompting as one skill. AISA measures three. "Direct AI Effectively" is a single content area in the framework. AISA splits it into prompt structure, iteration quality, and context architecture — because Anthropic's 10,000-conversation study showed that iteration alone is a 2x multiplier for effective AI use. Treating it as a sub-skill buries the most important signal.
The DOL treats AI applications as one area. AISA measures four. "Explore AI Uses" covers everything from productivity tools to decision-support systems. AISA scores workflow integration, task decomposition, domain-specific application, and tool ecosystem awareness independently — because someone who uses AI for drafting emails and someone who orchestrates multi-tool automated pipelines need different proficiency profiles.
The DOL checks competency. AISA scores proficiency depth. Can the worker evaluate AI outputs? The framework treats that as a yes/no competency. How well do they evaluate them — do they trust everything at face value, check occasionally, have a systematic verification process, or build verification into their architecture? That's a proficiency question, and it's what AISA's calibrated rubric answers on a multi-level scale for every criterion.
Curious about your AI Fluency?
AISA helps you measure, prove and improve your AI skills — free report in a 20-minute chat.
Where Fluency Goes Beyond Literacy
AISA measures skills the DOL framework doesn't isolate as separate competencies:
Task decomposition — how someone breaks a problem into AI-suitable versus human-judgment pieces. Not named in the DOL framework at all. But it's what separates someone who dumps an entire brief on ChatGPT from someone who strategically delegates the right subtasks while keeping judgment calls in human hands.
Iteration as a standalone skill — the DOL mentions "iterating on outputs" as one of five prompting sub-skills. AISA treats it as a top-priority standalone criterion because empirical evidence identifies it as the single strongest predictor of effective AI use.
Context architecture at depth — the DOL says "supplying relevant input data." AISA measures the full range from ad-hoc pasting to building persistent memory layers, multi-conversation workflows, and reusable system prompts. The gap between someone who pastes a document into a chat window and someone who builds context architectures for their team is the gap between literacy and fluency.
Calibrated proficiency scoring — every criterion is scored on a rubric calibrated by a separate AI review pass, producing a proficiency profile that tells you not just what someone can do but how well they do it. The DOL defines competency areas; AISA scores the depth within each one.
How AISA Embodies the DOL's Seven Delivery Principles
The framework doesn't just define what to teach — it specifies how effective AI education should be delivered. AISA's assessment methodology already embodies all seven principles:
| DOL principle | How AISA implements it |
|---|---|
| Experiential learning | Live conversation with interactive exercises and adaptive difficulty — not multiple choice |
| Embed in context | Questions adapt to the candidate's role and industry automatically |
| Complementary human skills | Critical thinking and judgment are explicitly measured, not assumed |
| Address prerequisites | Difficulty auto-calibrates to the candidate's level from the start |
| Pathways for continued learning | AI Coach delivers personalised daily lessons built from each person's assessment gaps |
| Prepare enabling roles | Team assessments give L&D leaders org-level readiness data and benchmarks |
| Design for agility | AI knowledge base updates weekly to reflect the latest tools, models, and capabilities |
The DOL calls for "interactive prompt exercises" and "progressive difficulty levels" — that describes AISA's exercise system. It calls for "side-by-side human comparisons" — that describes AISA's output evaluation games. The framework's delivery principles read like a spec sheet for something that already exists.
Two Independent Frameworks, One Assessment
This is the second major external framework to confirm that AISA's assessment covers the right skills — following the Anthropic AI Fluency Index comparison earlier this year.

Both frameworks were developed independently. One is the largest empirical study of effective AI use ever published (9,830 conversations analysed). The other is the U.S. federal government's official definition of what every worker needs to know about AI. Both confirm the same thing: the skills AISA measures are the skills the best available evidence says matter.
What This Means for Employers and L&D Leaders
If you're responsible for workforce AI readiness, TEN 07-25 just gave you a checklist. The five content areas tell you what your training programs should cover. The seven delivery principles tell you how to deliver them effectively.
But a checklist doesn't tell you where your team actually stands. It doesn't tell you who already has strong prompting skills but poor critical evaluation, who integrates AI deeply into their workflow but ignores safety, or who talks a good game about AI but has never actually verified an output.
That's the gap between a framework and an assessment. The DOL defined the standard. An AI fluency assessment tells you whether your workforce meets it — and where to invest in training.
AISA's assessment covers 100% of what the DOL says matters, scores the proficiency depth that training budgets depend on, and produces actionable reports for every individual and team.
Explore the full methodology, check the latest AI proficiency benchmarks, or take the free assessment to see where you stand.
Independence note: AISA was designed and built independently, before the publication of the DOL's AI Literacy Framework. The U.S. Department of Labor does not own, endorse, accredit, or directly contribute to AISA. TEN 07-25 and the attached AI Literacy Framework are publicly available government guidance. This comparison is our own analysis of how our pre-existing assessment framework aligns with the DOL's published competency areas.
Source: Training and Employment Notice No. 07-25, U.S. Department of Labor, Employment and Training Administration (February 13, 2026). Attachment I: The Department of Labor's Artificial Intelligence Literacy Framework.

Ozan Dagdeviren
Founder of AISA — the AI skills assessment platform used by professionals worldwide to measure, certify, and develop their AI fluency. More about AISA
Curious about your AI Fluency?
AISA helps you measure, prove and improve your AI skills — free report in a 20-minute chat.