![Anthropic's 10K-Conversation Study Validates AISA's Framework [White Paper]](/blog-images/anthropic-vs-aisa.png)
Anthropic's 10K-Conversation Study Validates AISA's Framework [White Paper]
93% of Anthropic's AI fluency behaviours are already in AISA's rubric. Full cross-reference: what aligns, where we surpass, and what's next.
Anthropic published the AI Fluency Index — the most comprehensive empirical study of how people actually use AI. Their team analysed 9,830 multi-turn conversations on Claude.ai, identifying the observable behaviours that distinguish fluent AI users from everyone else.
We cross-referenced every one of their findings against AISA's 11-criterion assessment framework. Not to prove we're right — to find out where we're wrong.
The result: 93% of the behaviours Anthropic identifies as defining AI fluency are already assessed in AISA's framework.
Key Findings
-
Anthropic's #1 signal — iteration — is AISA's #1 priority. P2 (Iterative Dialogue) sits in our highest-priority assessment tier. 10,000 conversations confirm this design choice. Users who iterate are 5.6x more likely to question AI reasoning.
-
The "polished output trap" validates AISA's persona system. Anthropic found professional-looking AI outputs suppress critical thinking (−5.2pp fact-checking, −3.1pp questioning reasoning). This is exactly the behaviour AISA's Copy-Paster persona detects and scores against.
-
4 of AISA's 11 criteria have no equivalent in Anthropic's framework. AI Fundamentals, Tool Landscape, Domain Application, and Safety require conversational probing that chat-log observation cannot perform.
Criterion-by-Criterion Cross-Reference
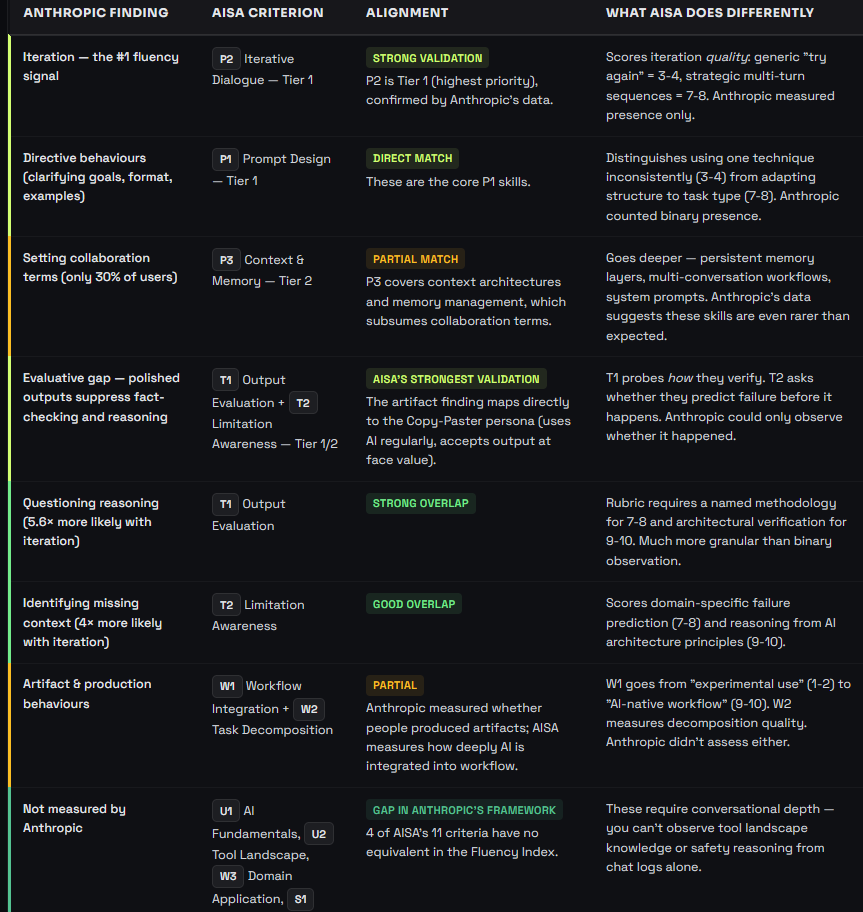
Anthropic identified 9 observable behaviours across three categories: how people describe tasks to AI, how they evaluate output, and how they delegate work. AISA assesses all three — and scores them on a 1–10 rubric rather than binary presence/absence.
Where We Go Even Deeper
4 of AISA's 11 criteria have no equivalent in Anthropic's framework. Anthropic's researchers explicitly acknowledged this gap — they listed 13 "unobservable" behaviours that matter for AI fluency but are invisible in chat logs. AISA's conversational assessment approach surfaces four of them directly:
- U1 (AI Fundamentals) — mental model of how AI works. Requires direct probing; invisible in natural chat behaviour.
- U2 (Tool Landscape) — knowledge of the AI ecosystem across multiple platforms. Can't observe multi-tool awareness on a single platform's logs.
- W3 (Domain Application) — AI use tailored to a specific profession. Domain context is lost in platform-agnostic analysis.
- S1 (Safety & Responsibility) — risk awareness, data boundaries, downstream impact thinking. Anthropic listed safety-related behaviours among their 13 unobservable items.
A Fundamentally Different Method
The difference isn't just what we measure — it's how.
Anthropic observed behaviour passively at scale: 9,830 conversations, binary classifiers, presence or absence of behaviours. Valuable for identifying patterns across populations.
AISA assesses behaviour actively through structured conversation: a dual-track AI system where one model talks to the candidate while a separate model evaluates independently. Each of 11 criteria is scored on a calibrated 1–10 rubric, with a final Opus-calibrated review pass that adjusts for systematic biases.
Observation tells you what people do. Conversation tells you why they do it, what else they know, and what they'd do differently in higher-stakes situations.
Both matter. But if you're certifying someone's AI skills or evaluating AI readiness across a team, you need the second kind.
What This Means
The most rigorous empirical AI fluency research published to date independently confirms that AISA's framework captures the right skills, measures dimensions that observation alone cannot reach, and does so through a method purpose-built for depth and accuracy.
AISA reports and certifications reflect real, validated AI proficiency — grounded in the same behaviours that large-scale research identifies as defining AI fluency.
What We're Doing Next
No framework is perfect. Anthropic's dataset surfaced specific areas where we can tighten our assessment:
- Collaboration framing — only 30% of users set interaction terms with AI. We're making this an explicit scoring anchor in our Context & Memory criterion (P3).
- The polished output trap — professional-looking AI artifacts suppress critical evaluation (−5.2pp). We're adding targeted probes for this specific blind spot in our Critical Thinking criteria.
- Iteration as a gateway signal — with a 2x fluency multiplier, we're exploring how to use iteration quality as an earlier signal in our adaptive difficulty system.
These are additive improvements — they sharpen our framework without changing its architecture. Exactly what you want from external validation: confirmation that the foundation is sound, with specific coordinates for where to build next.
Independence note: AISA was designed and built independently, before the publication of Anthropic's AI Fluency Index. Anthropic does not own, endorse, accredit, or directly contribute to AISA. The AI Fluency Index is publicly available research. This comparison is our own analysis of how our pre-existing framework aligns with their independently published findings.

Ozan Dagdeviren
Founder of AISA — the AI skills assessment platform used by professionals worldwide to measure, certify, and develop their AI fluency. More about AISA
Ready to try the free AI skills assessment yourself?